Things will go wrong, and that’s why we have replication and recovery
Things will go wrong with your software, or your hardware, or from something completely out of your control. But, we can plan for such failures, thus minimizing their impact. OpenShift supports this via the replication and recovery functionality.
Replication
Let’s walk through a simple example of how the replication controller can keep your deployment at a desired state. Assuming you still have the dc-metro-map project running we can manually scale up our replicas to handle increased user load.
Terminal access
https://console-openshift-console.apps.example.redhatgov.io/terminal
Goto the terminal and try the following:
$ oc scale --replicas=4 dc/dc-metro-map
Check out the new pods:
$ oc get pods
Notice that you now have 4 unique pods available to inspect. If you want go ahead and inspect them, using ‘oc describe pod/POD NAME’. You can see that each has its own IP address and logs.
Web Console access
https://console-openshift-console.apps.example.redhatgov.io
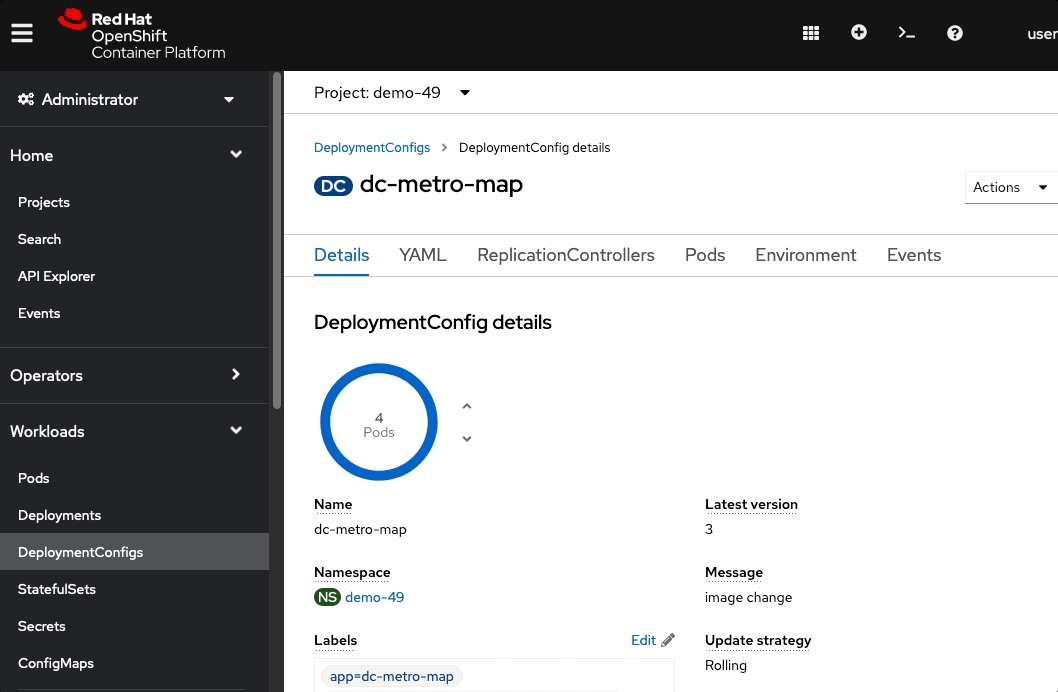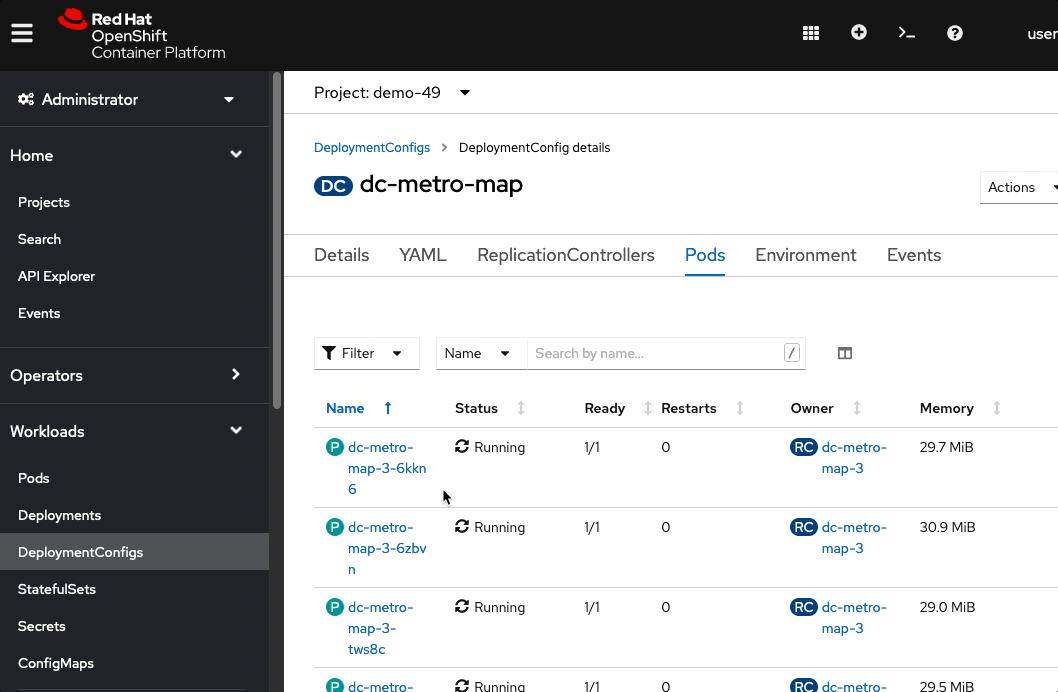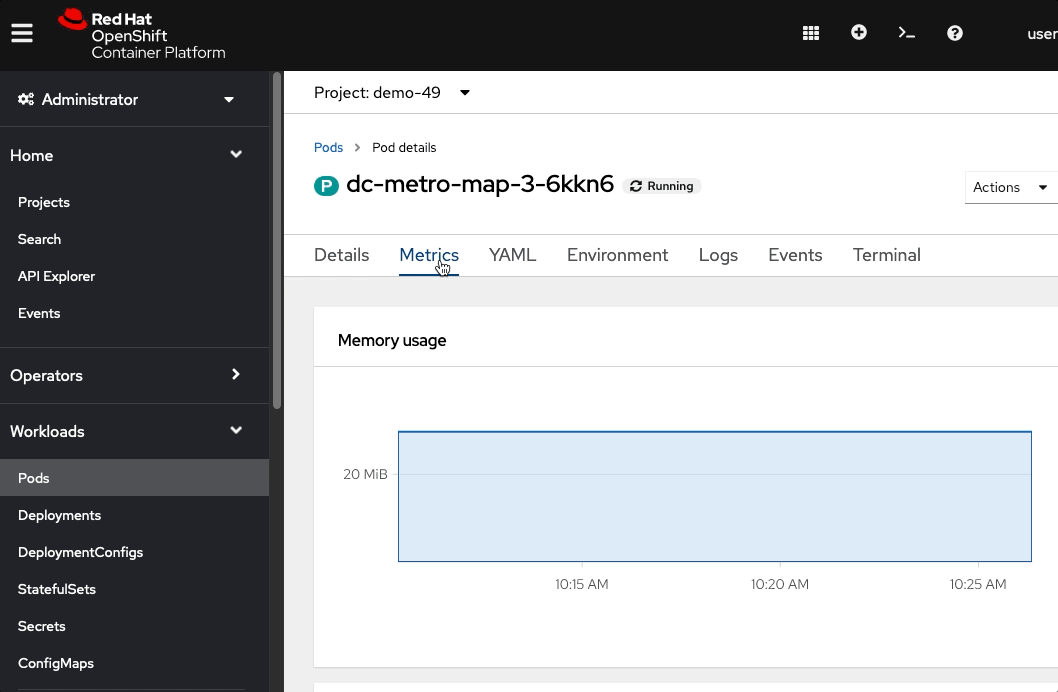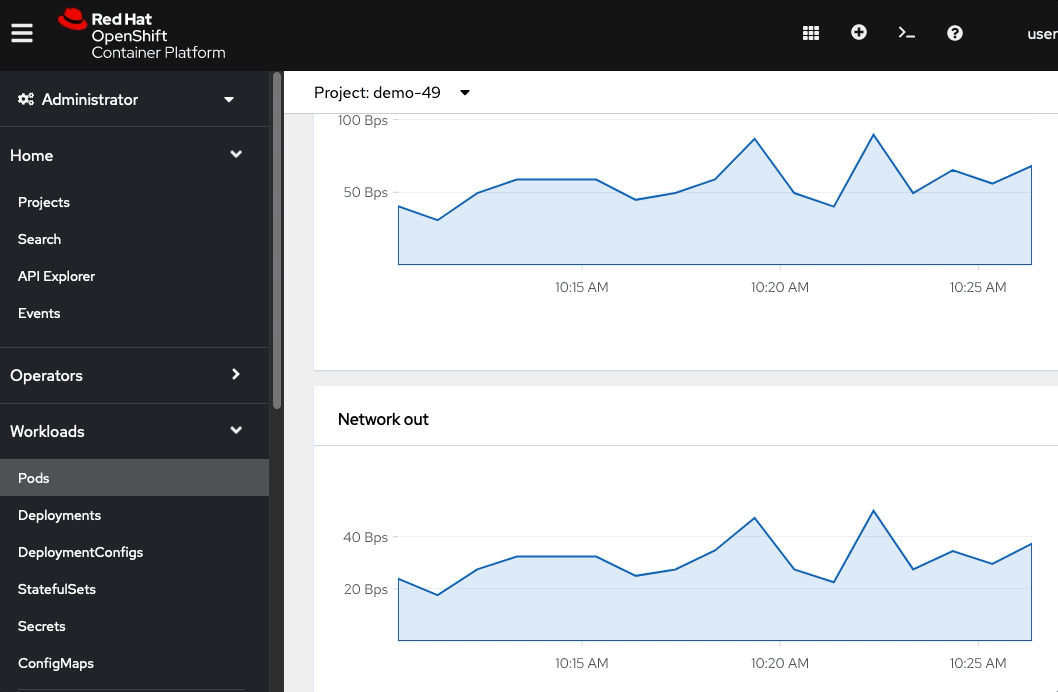
Click "Workloads", then "DeploymentConfigs", and then "dc-metro-map"
In the Deployment Config Details, click the up arrow 3 times.The deployment should indicate that it is scaling to 4 pods, and eventually you will have 4 running pods. Keep in mind that each pod has it's own container which is an identical deployment of the webapp. OpenShift is now (by default) round robin load-balancing traffic to each pod.
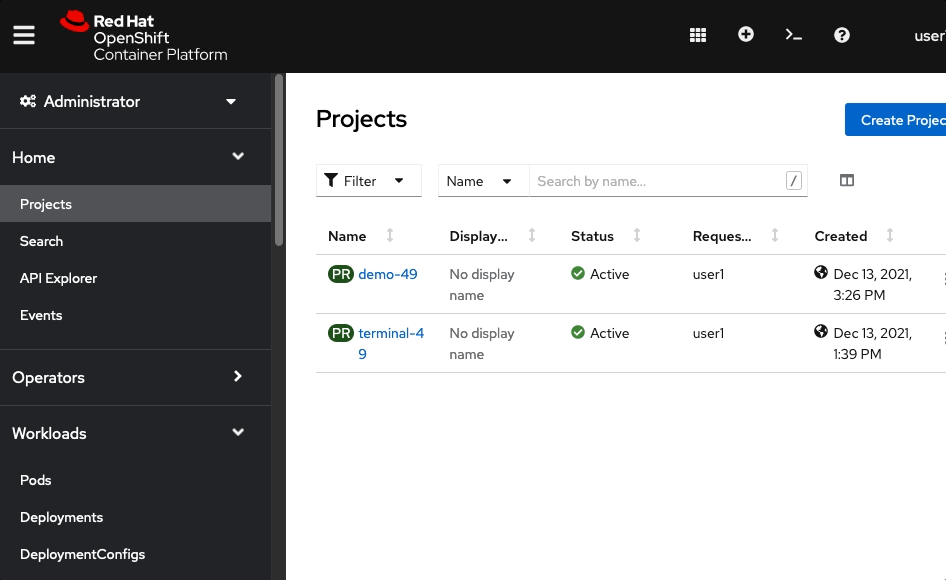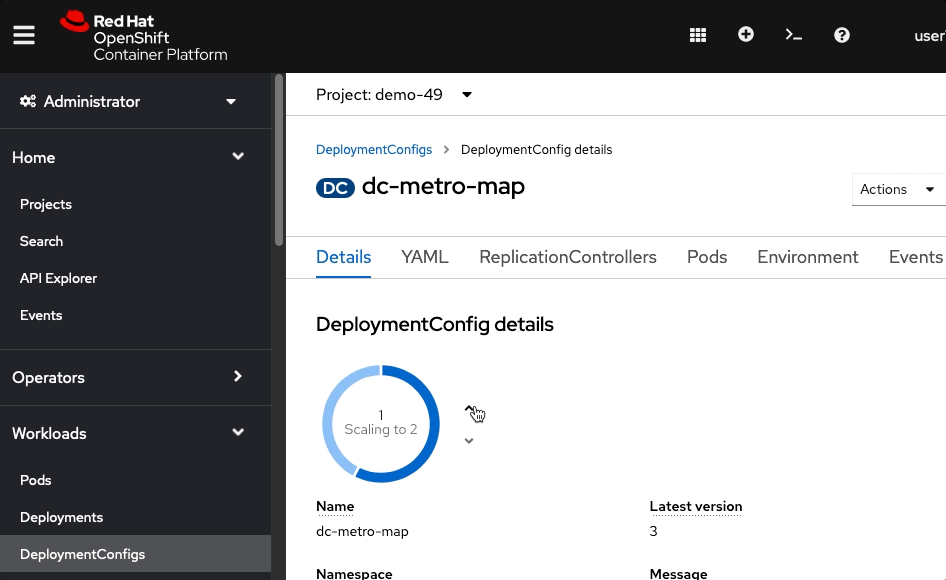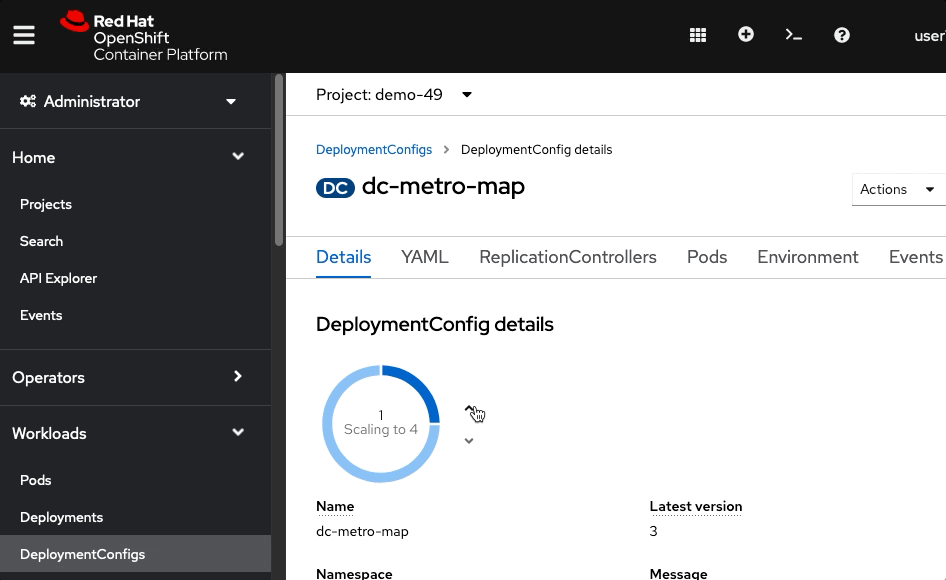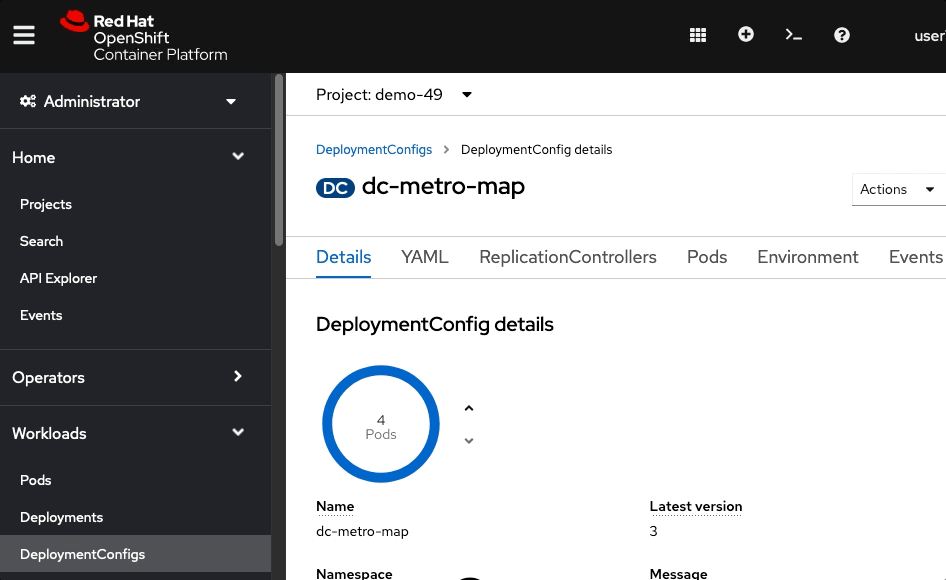
Click the Pods tab, one of the pods (ex: dc-metro-map-X-XXXX), and metricsNotice that you now have 4 unique webapp pods available to inspect. If you want go ahead and inspect them you can see that each has its own IP address and logs.
So you’ve told OpenShift that you’d like to maintain 4 running, load-balanced, instances of our web app.
Workshop Details
| Domain |
|
|
| Workshop | ||
| Student ID |
Workshop Details
| Domain |
|
|
| Workshop | ||
| Student ID |