Recovery
Okay, now that we have a slightly more interesting replication state, we can test a service outages scenario. In this scenario, the dc-metro-map replication controller will ensure that other pods are created to replace those that become unhealthy. Let’s forcibly inflict an issue and see how OpenShift responds.
Terminal access
https://console-openshift-console.apps.example.redhatgov.io/terminal
Choose a random pod and delete it:
$ oc get pods
$ oc delete pod/PODNAME
$ oc get pods -w
If you’re fast enough you’ll see the pod you deleted go “Terminating” and you’ll also see a new pod immediately get created and transition from “Pending” to “Running”. If you weren’t fast enough you can see that your old pod is gone and a new pod is in the list with an age of only a few seconds.
You can see the more details about your deployment configuration with:
$ oc describe dc/dc-metro-map
Web Console access
https://console-openshift-console.apps.example.redhatgov.io
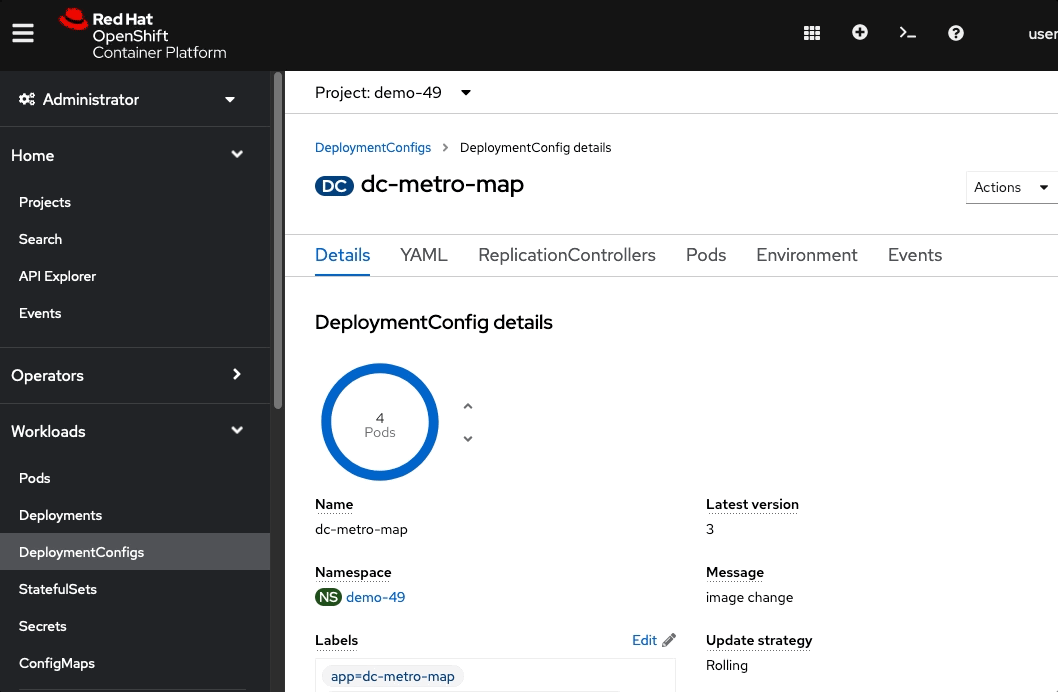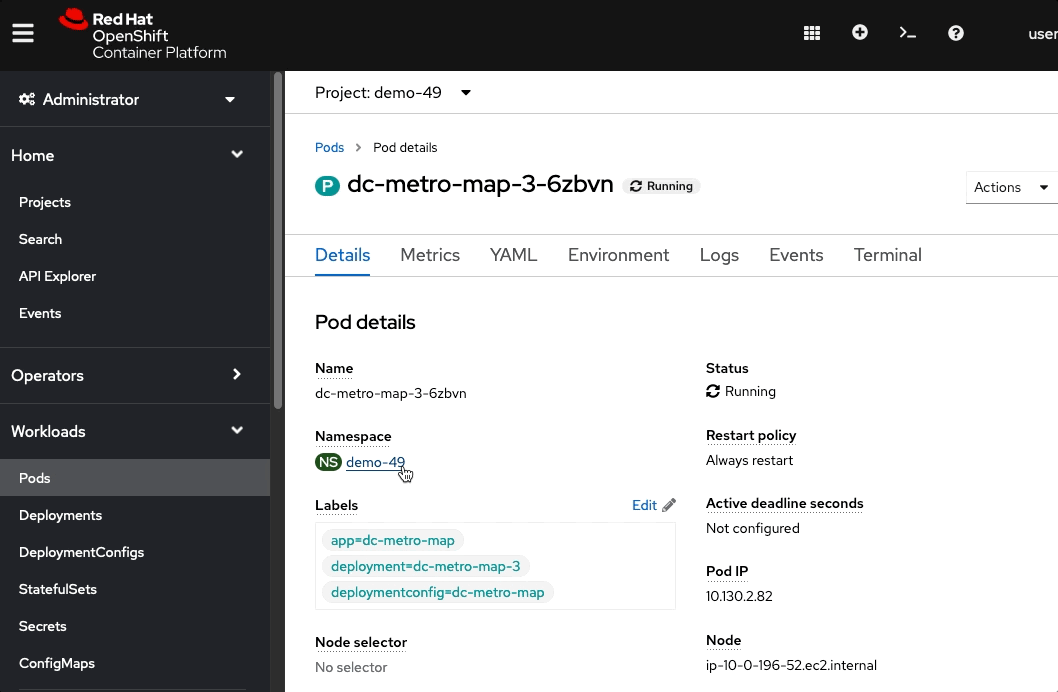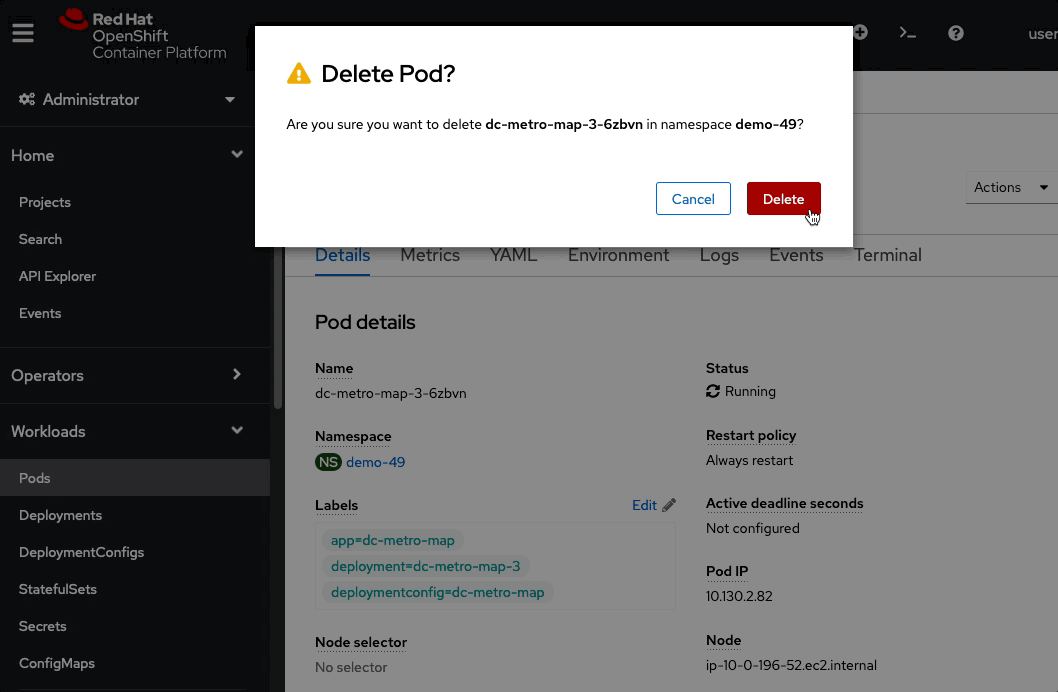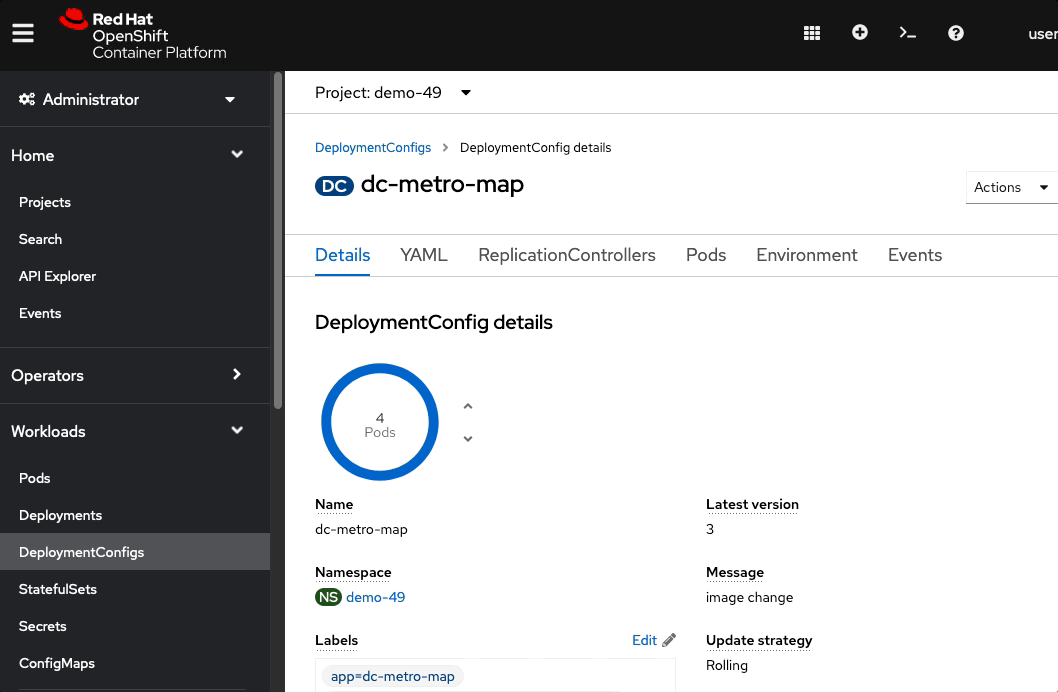
From the browse pods list:
Click one of the running pods (not a build pod)
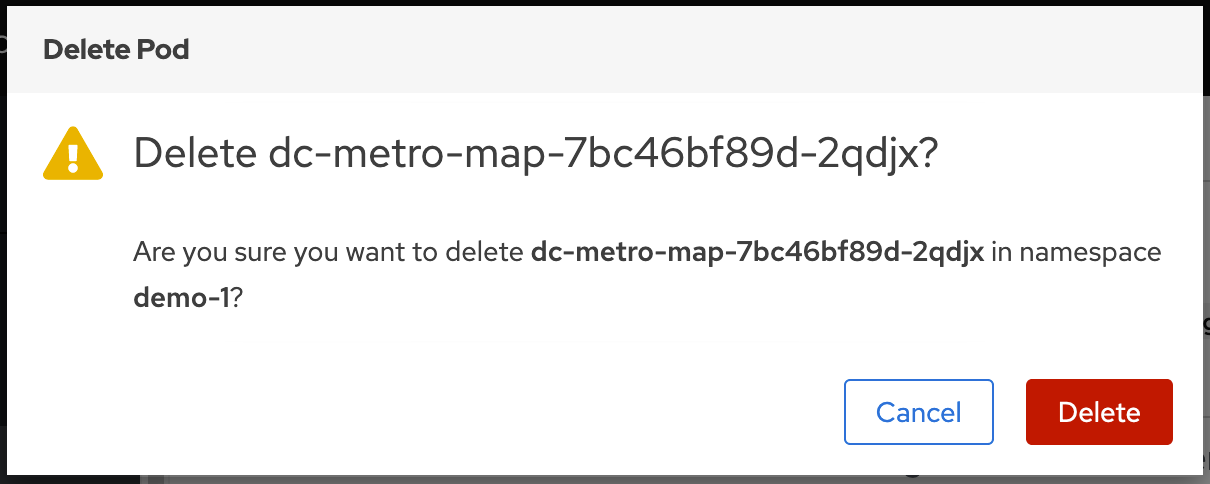
Click the "Actions" button in the top right and then select "Delete Pod"
Now click the "Delete" button in the popup to confirm the pod deletion
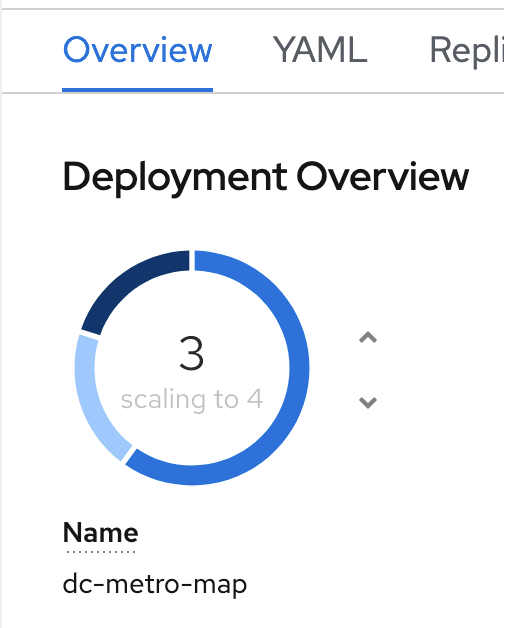
Quickly switch back to the deployment configuration overview
If you’re fast enough you’ll see the pod you deleted unfill a portion of the deployment circle, and then a new pod fill it back up.
Workshop Details
| Domain |
|
|
| Workshop | ||
| Student ID |
Workshop Details
| Domain |
|
|
| Workshop | ||
| Student ID |